-
페치조인(fetch Join )이란SPRING/JPA 2021. 12. 3. 02:24반응형
페치(fetch)조인은
SQL에서 사용하는 조인의 종류는 아니고 JPQL에서 성능 최적화를 위해 제공하는 기능입니다.
이것은 연관된 엔티티나 컬렉션을 한 번에 같이 조회하는 기능인데 join fetch 명령어로 사용할 수 있습니다.
페치 조인을 사용해서 회원(Member) 엔티티를 조회하면서 연관된 팀(Team) 엔티티도 함께 조회하는 JPQL을 실행해보겠습니다.
이해를 돕기 위해 회원, 팀 엔티티부터 순서대로 살펴보겠습니다.
Member 엔티티 23~25 라인을 보시면 Team엔티티와 N:1 관계, 지연 로딩으로 설정되어 있는걸을 확인하실 수 있습니다. (FetchType.LAZY)

Team 엔티티 23~24 라인을 보시면 Member엔티티와 양방향 매핑으로 되어있다는 것을 확인하실수 있습니다.
다음으로는 MemberRepository를 살펴보겠습니다.
MemberRepository 두 엔티티(Member, Team)와 SELECT를 위한 MemberRepository까지 살펴보았습니다.
이제 TEST를 해보겠습니다.
일반 조인 회원과 팀 엔티티를 각각 저장시켜서 (45~53 라인)
쿼리문을 보기 위해 강제로 flush, clear 시켰습니다. (55~56 라인)
이후 Member엔티티를 조회하는 쿼리문을 확인해보겠습니다. (58~61 라인)
팀 객체 확인하기 (61 라인)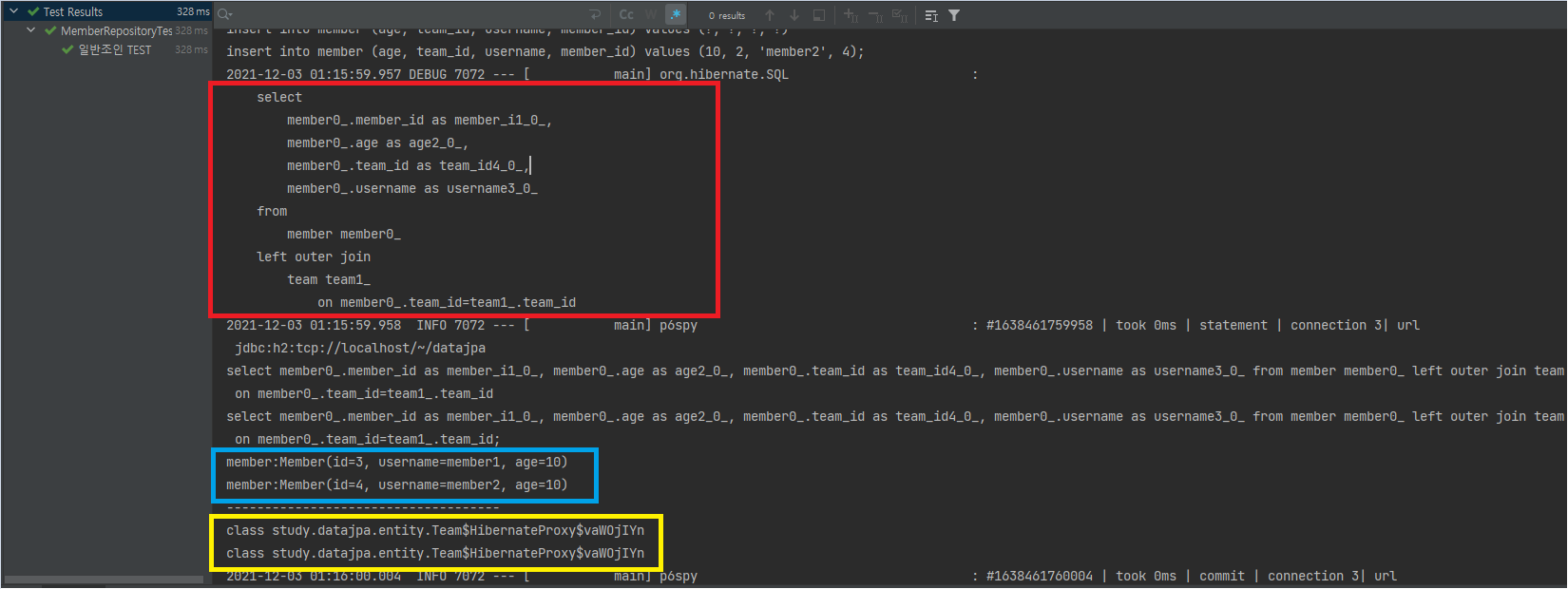
쿼리 결과물 보시다시피 SQL의 SELECT 절을 보시면 Member만 조회하고 조인했던 Team은 전혀 조회되지 않는 걸 보실 수 있습니다.
(JPQL은 결과를 반환할 때 연관관계까지 고려하지 않는다. 단지 SELECT 절에 지정한 엔티티만 조회할 뿐이다)
따라서 Member엔티티만 조회를 해오고, 지연 로딩으로 설정되어 있어서 Team엔티티는 프록시 객체로 가져옵니다.
이후 Team엔티티의 정보를 조회하면 ex)member.getTeam().getName()
Team엔티티의 정보를 위한 SELECT 쿼리가 DataBase에 별도로 나갑니다. (N + 1 문제)이러한 문제를 해결하기 위해 드디어 페치 조인을 사용합니다.
MemberRepository에 페치 조인을 추가해보겠습니다.
MemberRepository 추가 23라인을 보시면 새로운 페치 조인을 위한 join fetch가 추가되었습니다.
바로 테스트해보겠습니다.

페치 조인 아까와 동일하게 각 엔티티를 저장, 조회한 후 결과를 보겠습니다.

SELECT문을 보시면, 이번에는 페치 조인을 사용해서 회원 엔티티를 조회하면서 연관된 팀 엔티티도 함께 조회하는 것을 볼 수 있습니다.
또한 아까는 프록시 객체로 가져왔던걸 이번에는 Team 엔티티를 정확하게 가져옵니다.참고로 페치 조인은 글로벌 로딩 전략(fetch = FetchType.LAZY)보다 우선한다.
이런 페치 조인을 사용하면 SQL 한 번으로 연관된 엔티티들을 함께 조회할 수 있어서 SQL 호출 횟수를 줄여 성능을 최적화할 수 있습니다.
최적화를 위해 글로벌 로딩 전략을 즉시 로딩으로 설정하면 애플리케이션 전체에서 항상 즉시 로딩이 일어난다.
(사용하지 않는 엔티티를 자주 로딩하므로 성능에 악영향을 미칠 수 있다.)
따라서 글로벌 로딩 전략은 지연 로딩으로 설정하고 최적화가 필요하면 앞에서와 같이 페치 조인(fetch join)을 적용하는 것이 효과적이다.페치 조인의 한계
1. 페치 조인 대상에는 별칭을 줄 수 없다.
- JPA 표준에서는 지원하지 않지만 하이버네이트를 포함한 몇몇 구현체들은 페치 조인에 별칭을 지원하지만 별칭을 잘못 사용하면 연관된 데이터 수가 달라져서 데이터 무결성이 깨질 수 있으므로 사용하지 않는 것이 좋다.2. 둘 이상의 컬렉션을 페치 할 수 없다.
- 구현체에 따라 되기도 하는데 컬렉션 * 컬렉션의 카테시안 곱이 만들어지므로 주의해야 한다. 하이버네이트를 사용하면 예외가 발생한다.3. 컬렉션을 페치 조인하면 페이징 API(setFirstResult, setMaxResults)를 사용할 수 없다.
- 컬렉션(일대다)이 아닌 단일 값 연관 필드(일대일, 다대일)들은 페치 조인을 사용해도 페이징 API를 사용할 수 있다.
- 하이버네이트에서 컬렉션을 페치 조인하고 페이징 API를 사용하면 경고 로그를 뱉는다.--컬렉션을 페치 조인하고 페이징API를 사용하면 메모리에서 페이징 처리를 진행한다.
--데이터가 적으면 상관없겠지만 데이터가 많으면 성능 이슈와 메모리 초과 예외가 발생할 수 있기 때문이다.
다음 시간에는 똑같이 연관된 엔티티들을 SQL 한 번에 조회해오는 @EntityGraph을 알아보겠습니다.
참고 : 자바 ORM 표준 JPA 프로그래밍 : 스프링 데이터 예제 프로젝트로 배우는 전자정부 표준 데이터베이스 프레임(김영한 님 책)반응형'SPRING > JPA' 카테고리의 다른 글
@EntityGraph 사용법 (7) 2021.12.06 Spring Data JPA(쿼리 메소드) (0) 2021.10.11 JPA(Java Persistence API)동작 방식 (0) 2021.10.10 JPA(Java Persistence API)의 시작 (6) 2021.10.10